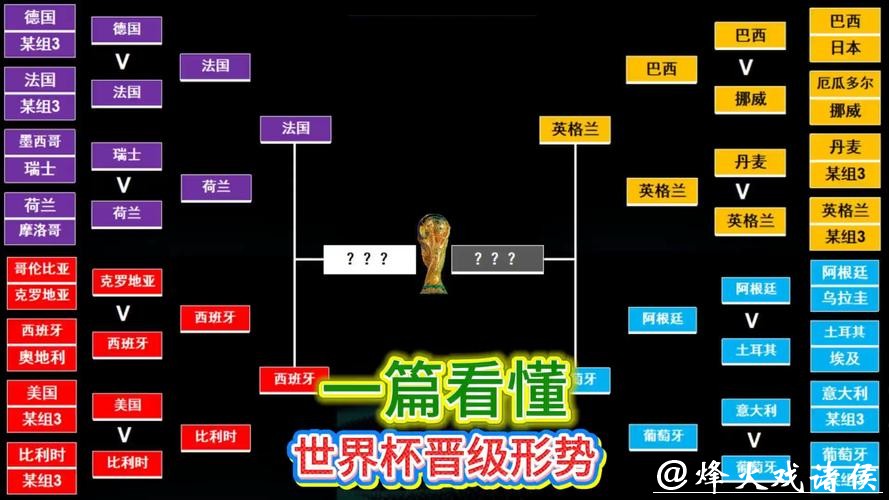
世界杯竞猜平台注册流程详解
2026-07-16
2026世界杯投注:利用数据模型提升胜率这一命题在当前全球体育博彩领域迅速升温,投注者渴望通过量化视角洞察球场的不确定性。与其依赖感性判断,不如让模型展示真实面貌:从球员状态到战术体系,再到赛程密度,数据的多维交织为决策提供可验证的依据。本文旨在搭建一套可执行的分析框架,让投注者在筹划策略时既能理解模型的技术细节,又能掌握落地方法,形成理论与实践的完整闭环。
核心思想与变量识别模型构建的第一步是明确“输入—处理—输出”逻辑,输入侧由宏观与微观变量构成:宏观变量包括主客场因素、气候、海拔以及赛会制特有的旅程压力;微观变量主要囊括球员的即时状态、伤病、临场战术调整以及对抗强度。为了避免信息冗杂,可采用特征重要性排序筛选关键指标,例如通过随机森林或互信息算法确定哪些因子对胜平负概率贡献最大。与此输入数据分层处理尤为关键:可将历史战绩、即时赛事数据与训练营信息拆分不同权重,以防模型过度依赖单一时间窗。输出侧则是投注场景最关心的概率分布,可采用_Brier Score_或_Log Loss_检验预测质量,确保模型不仅“看着准”,还能量化误差。

传统统计模型如泊松回归在处理比分预估、角球数量等离散事件上具有高可解释性,适合新手快速搭建原型。但随着世界杯参赛队伍扩容至48支,赛程复杂度大幅提升,传统模型对于非线性与交互效应的捕捉存在局限。此时可以引入梯度提升树、图神经网络或Transformer结构,利用上下文嵌入捕捉球队之间的隐性联系。例如设定球队作为节点、历次对战作为边,通过图结构学习战术风格传播模式,再结合球员位置数据构建多维特征张量。深度模型的优势在于捕捉高阶关联,但需警惕过拟合:应采用交叉验证、早停、Dropout等策略,并对每档赛事数据进行扩充与清洗,以降低噪声对参数收敛的影响。
数据源整合与质量控制数据模型的生命线在于输入质量。公开数据库如Opta、StatsBomb提供详尽赛事事件流,若预算允许,可订阅更细粒度的tracking data,提高模型对球队阵型切换的敏感度。对于非传统数据,社交媒体情绪、新闻报道、甚至训练营气候情况都能成为补充指标,但需建立可靠的ETL流程:先通过清洗、缺失值填补以及异常检测保证基础可用,再用时间对齐机制处理多源数据延迟。在质量监控阶段可设定动态阈值,比如若近期赛事中的控球率方差异常增大,即触发模型参数更新提醒。如此形成的闭环流程才能真正支持高频投注决策。

以某南美劲旅在2026世界杯预选赛的连续客场为例:模型整合了该队过去三年在海拔2000米以上场地的表现、主力中场的疲劳度指标以及对手高压逼抢效率。泊松模型预估该队场均进球1.15,失球0.9,但深度模型在加入心率变异与旅行距离特征后,将失球预测上调至1.3,明显揭示传统模型未捕捉到的隐性疲劳效应。结合赔率发现博彩公司对该队的胜赔低估风险,模型输出的投注建议是减仓胜负方向,转而关注总进球小于2.5的组合。此案展示了多源数据与模型迭代的实际收益:不仅减少盲目下注,还能洞察盘口错价点。

模型再精妙也无法消除风险,因此需要在投注策略中嵌入Kelly比例或半Kelly分配,确保收益与波动之间保持可控关系。敏感度分析是风险控制的重要手段:通过扰动关键变量(例如主力前锋受伤概率)来观察模型输出弹性,若结果高度敏感,应降低仓位或等待更多信息。实时迭代方面,建议在小组赛与淘汰赛阶段设定不同参数:小组赛信息充足,更适合宏观变量,淘汰赛则可引入博弈树思维,将点球决胜、临场换人策略纳入模拟场景,提高模型的适应力。通过持续记录模型预测与实际结果之间的偏差,构建回溯库,为下一次世界杯周期提供可量化的改进依据。